

Microsoft anunció esta semana Tutel , una biblioteca para respaldar el desarrollo de modelos mixtos de expertos (MoE) , un tipo particular de modelo de IA a gran escala
Tutel, que es de código abierto y se ha integrado en fairseq, uno de los kits de herramientas de Facebook en PyTorch, está diseñado para permitir a los desarrolladores de todas las disciplinas de IA "ejecutar MoE de manera más fácil y eficiente", explicó una declaración de Microsoft.
Los MoE están formados por pequeños grupos de "neuronas" que solo están activas en circunstancias especiales y específicas. Las “capas” inferiores del modelo de MoE extraen las características y se solicita a los expertos que evalúen esas características. Por ejemplo, los MoE se pueden utilizar para crear un sistema de traducción, con cada grupo de expertos aprendiendo a manejar una parte separada del discurso o una regla gramatical especial.
En comparación con otras arquitecturas de modelos, los MoE tienen distintas ventajas. Pueden responder a las circunstancias con especialización, lo que permite que el modelo muestre una mayor variedad de comportamientos. Los expertos pueden recibir una combinación de datos y, cuando el modelo está en funcionamiento, solo unos pocos expertos están activos; incluso un modelo enorme necesita solo una pequeña cantidad de potencia de procesamiento.
De hecho, MoE es uno de los pocos enfoques demostrados para escalar a más de un billón de parámetros, allanando el camino para modelos capaces de impulsar la visión por computadora, el reconocimiento de voz, el procesamiento del lenguaje natural y los sistemas de traducción automática, entre otros. En el aprendizaje automático, los parámetros son la parte del modelo que se aprende a partir de los datos de entrenamiento históricos. En términos generales, especialmente en el dominio del lenguaje, la correlación entre el número de parámetros y la sofisticación se ha mantenido bien.
Tutel se centra principalmente en las optimizaciones de la computación específica de MoE. En particular, la biblioteca está optimizada para las nuevas instancias de la serie Azure NDm A100 v4 de Microsoft, que proporcionan una escala móvil de GPU Nvidia A100. Tutel tiene una interfaz "concisa" destinada a facilitar la integración en otras soluciones de MoE, dice Microsoft. Alternativamente, los desarrolladores pueden usar la interfaz de Tutel para incorporar capas independientes de MoE en sus propios modelos DNN desde cero.
“Debido a la falta de implementaciones eficientes, los modelos basados en MoE se basan en una combinación ingenua de múltiples operadores estándar proporcionados por marcos de aprendizaje profundo como PyTorch y TensorFlow para componer el cálculo del MoE. Esta práctica genera importantes gastos generales de rendimiento gracias a la computación redundante ”, escribió Microsoft en una publicación de blog. (Los operadores proporcionan un modelo con un conjunto de datos conocido que incluye las entradas y salidas deseadas). "Tutel diseña e implementa múltiples núcleos de GPU altamente optimizados para proporcionar operadores para el cálculo específico de MoE".
Tutel está disponible en código abierto en GitHub. Microsoft dice que el equipo de desarrollo de Tutel “integrará activamente” varios algoritmos emergentes de MoE de la comunidad en versiones futuras.
“MoE es una tecnología prometedora. Permite un entrenamiento holístico basado en técnicas de muchas áreas, como el enrutamiento sistemático y el equilibrio de la red con nodos masivos, e incluso puede beneficiarse de la aceleración basada en GPU. Demostramos una implementación eficiente de MoE, Tutel, que resultó en una ganancia significativa sobre el marco de fairseq. Tutel también se ha integrado [con nuestro] marco DeepSpeed , y creemos que Tutel y las integraciones relacionadas beneficiarán a los servicios de Azure, especialmente para aquellos que desean escalar sus grandes modelos de manera eficiente ”, agregó Microsoft.
[Fuente]: venturebeat.com
Rezaie, M.( 23 de Noviembre de 2021).A homeless in front of the Microsoft Vancouver.. [Fotografía]. Modificado por Carlos Zambrado Recuperado de unsplash.com
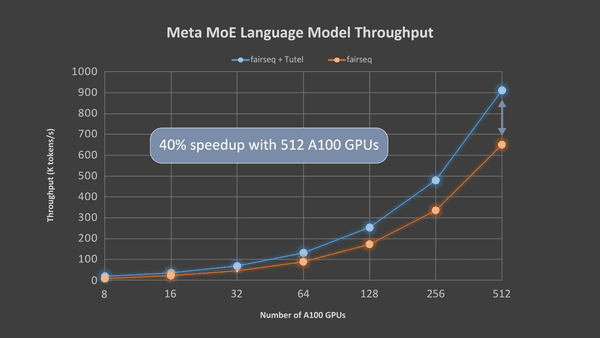
Anónimo.( 23 de Noviembre de 2021).Arriba: Para una sola capa de MoE, Tutel logra una aceleración de 8.49 veces en un nodo NDm A100 v4 con 8 GPU y una aceleración de 2.75 veces en nodos de 64 NDm A100 v4 con 512 GPU A100, afirma Microsoft. [Fotografía]. Modificado por Carlos Zambrado Recuperado de venturebeat.com




